數據倉庫 AI時代首選的Data API、數據處理與存儲支持服務
在人工智能浪潮席卷全球的今天,數據已成為驅動技術進化的核心燃料。面對海量、異構、實時涌現的數據,如何高效、可靠地進行采集、處理、存儲并提供服務,是每個組織構建AI能力時必須解答的命題。數據倉庫,這一歷經演進的數據管理范式,憑借其系統性、集成性和智能化的現代特性,正成為AI時代首選的綜合性數據API、處理與存儲支持服務平臺。
1. 統一、標準化的數據API層:連接AI與業務數據的橋梁
AI模型的訓練、推理與迭代,高度依賴于對高質量數據的便捷訪問。現代數據倉庫(如Snowflake、BigQuery、Databricks等)的核心優勢之一,便是提供了一套強大、統一且標準化的數據API接口。
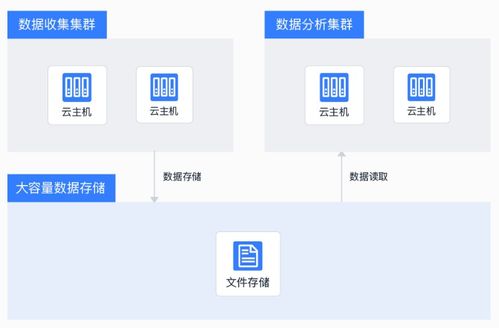
- 消除數據孤島:它將分散在業務數據庫、日志文件、應用系統乃至物聯網設備中的原始數據,通過ETL/ELT流程進行抽取、清洗與集成,匯聚成單一、可信的真相來源。這為AI應用提供了無需四處“打井”的集中取水點。
- 靈活的訪問接口:通過標準的SQL查詢接口、RESTful API、或與Python/Spark等分析生態的深度集成,數據倉庫讓數據科學家和算法工程師能夠像調用服務一樣,輕松獲取特征數據、訓練集或實時流數據。這種“數據即服務”的模式,極大地加速了AI從實驗到部署的周期。
- 安全與治理:作為統一入口,數據倉庫內置了精細的權限控制、數據血緣追蹤和訪問審計功能,確保在滿足AI模型數據需求的嚴格遵守數據安全與合規要求。
2. 強大的數據處理引擎:為AI準備高質量的“食材”
AI領域有句名言:“垃圾進,垃圾出。”數據預處理和特征工程占據了AI項目絕大部分工作量。現代數據倉庫內置了強大的大規模并行處理能力。
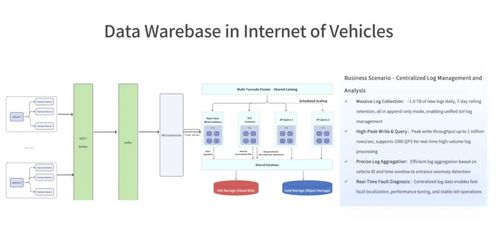
- 高性能計算:依托云原生的彈性架構,數據倉庫能夠對PB級數據進行復雜的轉換、聚合和窗口計算,快速生成用于模型訓練的結構化特征表。
- 支持多樣化處理范式:它不僅能處理傳統批量數據,更能無縫對接實時數據流,支持流批一體處理。這對于需要實時反饋和在線學習的AI應用至關重要。
- 與AI/ML工具鏈的融合:許多數據倉庫平臺已原生集成或深度優化了與主流機器學習框架(如TensorFlow、PyTorch)的協作,允許在數據存儲位置附近直接運行訓練任務,避免大規模數據移動帶來的成本和延遲。
3. 面向分析的智能存儲:成本、性能與規模的平衡
AI對數據存儲提出了前所未有的要求:海量規模、快速響應、多樣化的訪問模式以及可控的成本。現代數據倉庫的存儲層為此進行了深度優化。
- 分層存儲與智能優化:自動將熱數據、溫數據和冷數據分層存儲于不同性能/成本的介質中,并利用智能壓縮、列式存儲和自動聚類技術,在保證查詢性能的同時最大化降低存儲成本。
- 支持半結構化與非結構化數據:除了傳統的結構化表格,現代數據倉庫普遍支持原生存儲和查詢JSON、Parquet等格式的半結構化數據,甚至開始集成對圖像、文本等非結構化數據的處理能力,為多模態AI應用鋪平道路。
- 無限的彈性擴展:云數據倉庫徹底擺脫了傳統硬件的容量和性能限制,可根據AI工作負載的需求瞬間彈性伸縮,為模型訓練和推理提供按需供給的存儲資源。
4. 成為AI基礎設施的核心組件
數據倉庫在AI時代已超越了傳統“歷史數據分析庫”的范疇,演進為一個集數據集成、治理、處理、存儲和API化服務于一體的 “數據中樞” 。它通過提供一致、可靠、高效的數據服務,解決了AI項目在數據層面面臨的核心痛點:數據獲取難、質量差、處理慢、管理亂。
將數據倉庫作為AI項目的數據基座,意味著團隊可以將更多精力聚焦于算法創新和業務應用,而非復雜的數據工程運維。它不僅是AI時代的首選支持服務,更是構建企業智能化能力的戰略性基礎設施。一個設計良好、治理完善的數據倉庫,是釋放數據潛力、賦能AI創新的堅實基石。
如若轉載,請注明出處:http://www.wudima.cc/product/20.html
更新時間:2026-05-15 04:14:04