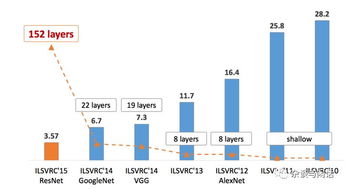
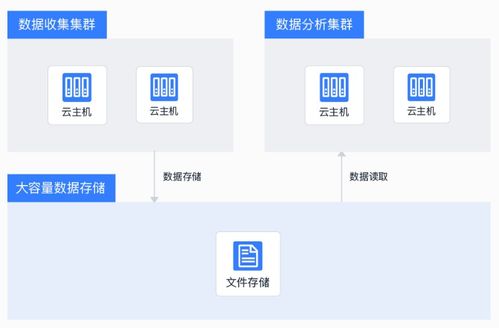
從架構到服務 NoSQL數據存儲與處理的基礎演變
隨著互聯網應用的爆炸式增長和數據結構日益復雜,傳統關系型數據庫在應對海量數據、高并發訪問和靈活數據模型方面的局限性逐漸顯現。NoSQL(Not Only SQL)應運而生,它不僅是一種數據庫技術,更代表了一種全新的數據存儲、處理與應用架構的設計哲學。其發展演變深刻影響了數據處理和存儲支持服務的形態與范式。
一、NoSQL基礎:核心理念與分類
NoSQL的核心在于擺脫傳統關系型數據庫的嚴格模式(Schema)、ACID事務和SQL查詢的束縛,追求更高的擴展性、靈活性和性能。根據數據模型的不同,主要分為以下幾類:
1. 鍵值存儲(如Redis、DynamoDB):結構簡單,通過唯一鍵訪問數據,適合緩存、會話存儲等場景。
2. 文檔數據庫(如MongoDB、Couchbase):以JSON/BSON等格式存儲半結構化文檔,模式靈活,適合內容管理、用戶配置等。
3. 列族數據庫(如HBase、Cassandra):按列族存儲數據,適合海量數據的分布式存儲與查詢,常見于大數據分析。
4. 圖數據庫(如Neo4j):以節點、邊和屬性存儲數據,專門優化了關系查詢,適用于社交網絡、推薦系統等。
這些類型為不同應用場景提供了針對性的解決方案,奠定了數據處理多樣化的基礎。
二、應用架構的演變:從集中到分布式
NoSQL的興起直接驅動了應用架構的深刻變革。
- 單體架構的解耦:傳統單體應用常與單一關系數據庫緊密耦合。NoSQL數據庫的多樣性允許開發者根據微服務或功能模塊的具體需求(如高讀寫、復雜關系、快速緩存)選擇最合適的數據存儲,推動了服務化與數據解耦。
- 分布式架構的普及:大多數NoSQL數據庫天生為分布式設計,支持數據分片(Sharding)和副本復制(Replication)。這使得應用架構能夠輕松實現水平擴展,通過添加更多廉價服務器來應對增長,而非依賴單一大型服務器的垂直升級。
- 多模型與混合持久化:現代復雜應用很少只使用一種數據庫。架構上常采用“混合持久化”策略,例如用Redis處理高速緩存和會話,用MongoDB存儲核心業務文檔,用Neo4j管理社交關系。這要求架構設計具備清晰的邊界和數據同步策略。
三、數據存儲與處理的演變:從單一到融合
數據處理范式隨著NoSQL的發展而不斷演進。
- 存儲與計算的分離:早期Hadoop生態(HDFS存儲 + MapReduce計算)已體現了存儲與計算分離的思想。現代云原生NoSQL服務(如Amazon S3 + Athena,或Snowflake架構)將這種分離推向極致,允許獨立擴展存儲層和計算層,提升了資源利用率和成本效益。
- 從批處理到實時流處理:傳統數據倉庫側重于T+1的批處理。以Apache Kafka為代表的消息隊列與NoSQL數據庫(如Cassandra)結合,構建了實時數據管道,支持流式處理(如Apache Flink、Spark Streaming),實現了事件驅動架構和實時分析。
- 事務與一致性的新平衡:NoSQL早期常犧牲強一致性(ACID)換取可用性與分區容錯性(遵循CAP定理)。但NewSQL(如Google Spanner、TiDB)和部分NoSQL數據庫(如MongoDB支持多文檔事務)開始尋求在分布式環境下提供更強的一致性保證,以滿足金融、交易等場景的需求。
四、數據處理和存儲支持服務的崛起
NoSQL的普及催生并重塑了整個數據處理和存儲的支持服務生態。
- 云托管數據庫服務(DBaaS):AWS DynamoDB、Azure Cosmos DB、Google Cloud Firestore等全托管服務,將NoSQL數據庫的運維復雜性(如擴縮容、備份、打補丁)完全抽象,開發者只需關注數據模型和API,極大提升了開發效率。
- 數據即服務平臺:云廠商提供從數據攝取、存儲、處理到分析的一站式平臺。例如,數據可通過Kafka流入,存儲在對象存儲或NoSQL數據庫中,由無服務器函數(如AWS Lambda)或流處理服務進行轉換,最終結果可被可視化工具查詢。這種服務化集成簡化了數據流水線的構建。
- 運維與監控服務的智能化:圍繞NoSQL集群,涌現出專業的監控、備份、遷移和安全服務。這些服務利用AI進行性能調優、異常檢測和容量預測,保障了大規模數據系統的穩定運行。
NoSQL的學習不僅是掌握幾種數據庫技術,更是理解一種以應用需求為導向、面向分布式和云環境的數據管理思維。從基礎的數據模型選擇,到宏觀的微服務與混合持久化架構,再到與實時處理和云服務的深度融合,NoSQL的演變軌跡清晰地指向了未來:數據處理與存儲將越來越作為一種可組合、彈性伸縮、高度自動化的基礎服務,無縫地支撐起智能時代的多元化應用創新。
如若轉載,請注明出處:http://www.wudima.cc/product/14.html
更新時間:2026-05-15 23:28:05