大數據課程筆記 Day18 數據處理與存儲支持服務解析
在數據驅動的時代,數據處理與存儲支持服務構成了大數據技術棧的基石。Day18的課程重點探討了這兩大核心領域的關鍵技術、架構設計及實踐應用,旨在構建高效、可擴展且可靠的數據基礎設施。
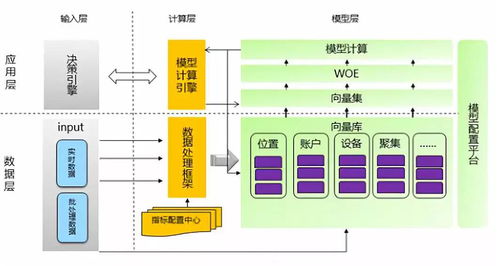
一、數據處理支持服務
數據處理涵蓋數據從原始形態到可分析狀態的整個生命周期,主要包括數據采集、清洗、轉換與集成。
- 數據采集與流處理
- 批量采集:適用于非實時場景,如使用Sqoop從關系數據庫導入HDFS,或通過Flume收集日志文件。
- 實時流采集:應對高時效性數據,常用Kafka作為消息隊列,實現數據緩沖與異步處理;結合Flink或Spark Streaming進行實時計算,支持事件時間處理與狀態管理。
- 技術要點:需關注數據源適配、吞吐量優化和端到端延遲控制,例如通過Kafka分區并行提升消費能力。
- 數據清洗與轉換
- 質量規則:定義完整性、一致性、準確性校驗規則,如使用Apache Griffin進行數據質量監測。
- ETL/ELT流程:傳統ETL(如Talend)在提取后轉換,適用于結構化數據;現代ELT依托云數據倉庫(如Snowflake)先加載后轉換,提升靈活性。
- 工具生態:Airflow或Dagster用于編排復雜工作流;dbt(Data Build Tool)支持SQL-centric的轉換,促進團隊協作。
- 數據集成與湖倉一體
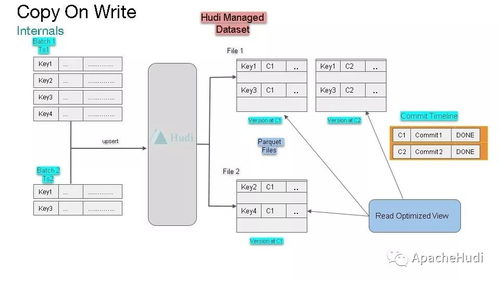
- 數據湖:以Delta Lake、Apache Iceberg為代表的表格格式,在對象存儲上提供ACID事務、模式演進能力,解決數據孤島問題。
- 湖倉融合:結合數據湖的靈活性與數據倉庫的性能,如Databricks Lakehouse架構,支持BI、ML等多工作負載。
二、數據存儲支持服務
存儲系統的選擇直接影響數據訪問效率、成本及治理能力。
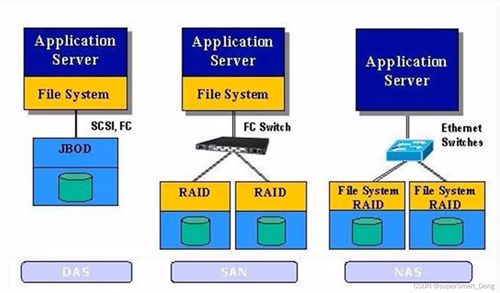
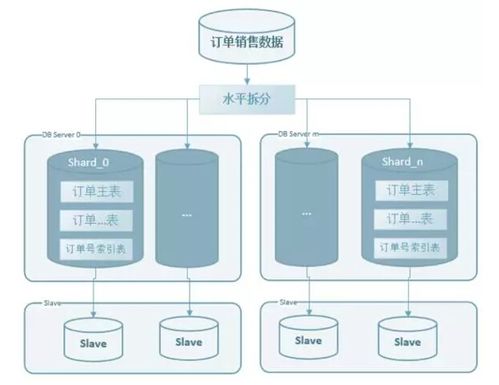
- 分布式文件系統
- HDFS:仍是大批量數據存儲的基石,適合順序讀寫,但面臨小文件治理挑戰。
- 云對象存儲:如AWS S3、Azure Blob Storage,提供無限擴展、高耐久性及低成本,成為數據湖的主流底座。
- 優化策略:通過合并小文件、使用ORC/Parquet列式格式提升查詢性能;生命周期策略自動化冷熱數據分層。
- NoSQL數據庫
- 鍵值存儲:Redis用于緩存與會話管理;DynamoDB支持高并發讀寫,適配微服務架構。
- 寬列存儲:Cassandra、HBase適合時間序列或稀疏數據,提供可線性擴展的寫入能力。
- 文檔存儲:MongoDB的靈活模式適用于半結構化數據,如JSON文檔。
- 選型考量:依據數據模型、一致性要求(CAP定理)及訪問模式(點查詢vs范圍掃描)進行選擇。
- 數據倉庫與OLAP引擎
- MPP數據倉庫:如Redshift、BigQuery,利用列存儲與向量化執行加速分析查詢。
- OLAP引擎:ClickHouse、Doris以極速聚合查詢見長;Presto/Trino實現跨源聯邦查詢,避免數據移動。
- 趨勢:云原生、存儲計算分離成為標配,支持彈性擴縮容與按需計費。
三、架構實踐與演進
- Lambda與Kappa架構:Lambda結合批流處理,保證數據一致性但維護復雜;Kappa以流處理為核心簡化鏈路,依賴狀態管理與事件溯源。
- 數據網格(Data Mesh):倡導領域導向的去中心化數據所有權,通過數據產品化與自助基礎設施提升協作效率。
- 運維與監控:利用Prometheus監控集群健康度;通過數據血緣(如Apache Atlas)追蹤數據流轉,保障合規性。
###
數據處理與存儲支持服務的設計需緊密對齊業務目標:實時場景優先流處理與低延遲存儲;探索性分析側重數據湖的靈活性;報表應用依賴高性能數倉。隨著存算分離、智能分層及開源標準化(如OpenTableFormat)的深化,數據基礎設施將更趨彈性、經濟與自動化。掌握這些核心服務,是構建健壯大數據平臺的關鍵一步。
如若轉載,請注明出處:http://www.wudima.cc/product/1.html
更新時間:2026-05-21 10:59:16